The MIT License (MIT) Copyright (c) [npm username] Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
type CapitalizeStr<Strextendsstring>= Strextends`${infer First}${infer Rest}` ?`${Uppercase<First>}${Rest}`:Str; type CapitalizeResult=CapitalizeStr<'tang'>
首先限制参数类型必须是字符串类型。
然后用 extends 为参数类型匹配公式,提取公式中的变量 First Rest,并通过 Uppercase 封装。
type ReverseArr<Arrextendsunknown[]>= Arrextends[infer First,...infer Rest] ?[...ReverseArr<Rest>,First] :Arr; type ReverseArrResult=ReverseArr<[1,2,3,4,5]>
type BuildArray< Lengthextendsnumber, Ele= unknown, Arrextendsunknown[]=[] >=Arr['length']extendsLength ?Arr :BuildArray<Length,Ele,[...Arr,Ele]>; type Add<Num1extendsnumber,Num2extendsnumber>= [...BuildArray<Num1>,...BuildArray<Num2>]['length']; type AddResult=Add<32,25>
type TExtract<T,U>=TextendsU?T: never type ExtractRes=TExtract<'aa'|'bb','aa'>
Omit 删除过滤索引
通过高级类型 Pick、Exclude 组合,删除过滤索引。
type TOmit<T,KextendskeyofT>=Pick<T,Exclude<keyof T,K>> type OmitRes=TOmit<{ name:'aa', age:18},'name'>
Awaited 用于获取 Promise 的 valueType
通过递归来获取未知层级的 Promise 的 value 类型。
type TAwaited<T>= Textendsnull|undefined ?T :Textendsobject&{then(onfulfilled: infer F): any } ?Fextends((value: infer V,...args: any)=> any) ?Awaited<V> : never :T; type AwaitedRes=TAwaited<Promise<Promise<Promise<string>>>>
# 以拓扑排序规则在包含该脚本的每个包中运行 npm run dev 脚本。 lerna run dev --stream --sort # 以拓扑排序规则在包含该脚本的每个包中运行 npm run build 脚本。 lerna run build --stream --sort
构建指定包:
# 在 packageA 包中运行 npm run dev 脚本。 lerna run dev --stream --scope=packageA # 在 packageA 包中运行 npm run build 脚本。 lerna run build --stream --scope=packageA
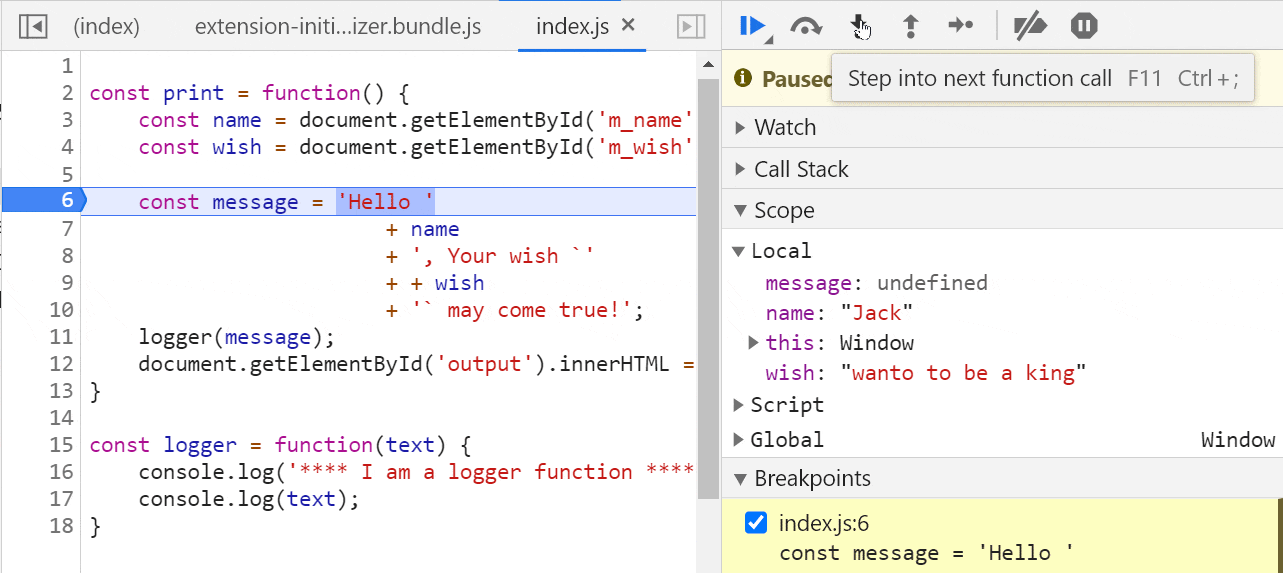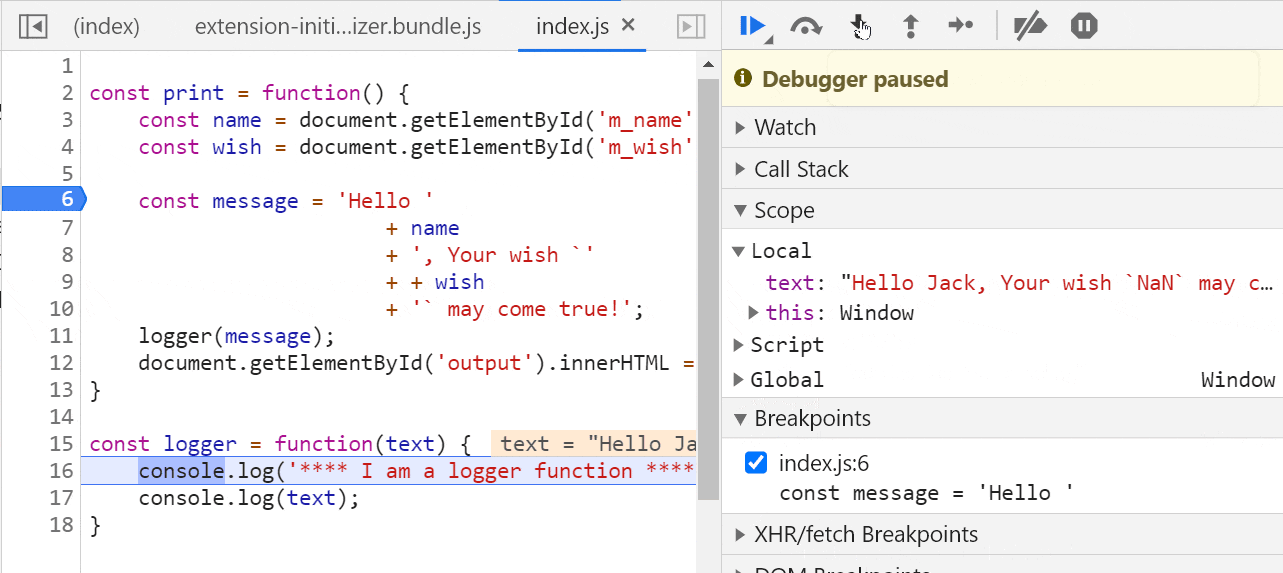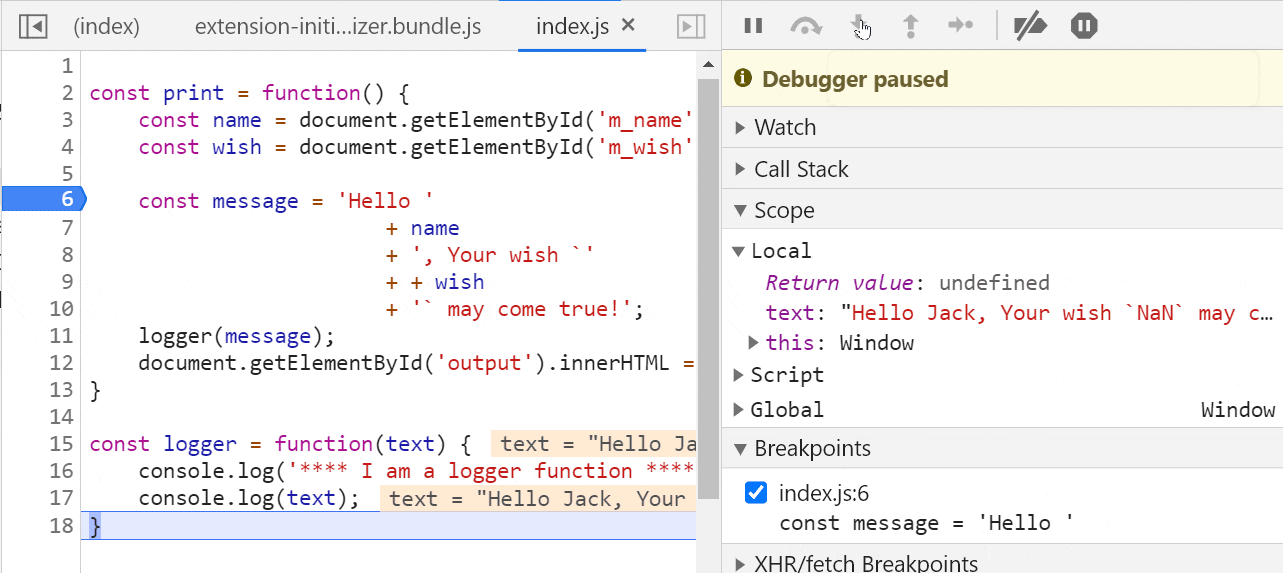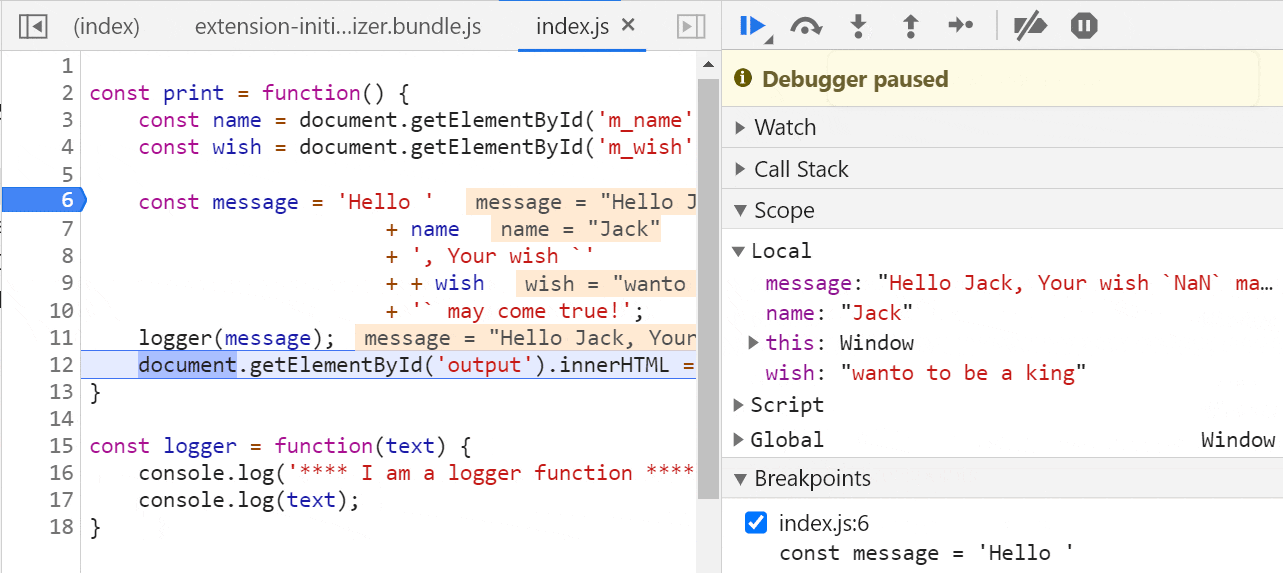
要启用 JavaScript 调试,你需要安装一个名为 Debugger for Chrome 的插件。
你可以在 VS Code 的 Extensions 面板中搜索此扩展并安装它。
安装后,单击左侧的 Run 选项并创建配置以运行/调试 JavaScript 应用程序。
将创建一个名为 launch.json 的文件,其中包含一些设置信息。它可能看起来像这样:
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: <https://go.microsoft.com/fwlink/?linkid=830387> "version":"0.2.0", "configurations":[ { "type":"chrome", "request":"launch", "name":"Debug the Greet Me app", "url":"<http://localhost:5500>", "webRoot":"${workspaceFolder}" } ] }
function test time(){ var users=[ { firstname:"Tapas", lastname:"Adhikary", hobby:"Blogging" }, { firstname:"David", lastname:"Williams", hobby:"Chess" }, { firstname:"Brad", lastname:"Crets", hobby:"Swimming" }, { firstname:"James", lastname:"Bond", hobby:"Spying" }, { firstname:"Steve", lastname:"S", hobby:"Talking" } ]; vargetName=function(user){ return user.lastname; } // Start the time which will be bound to the string 'loopTime' console.time("loopTime"); for(let counter =0; counter <1000*1000*1000; counter++){ getName(users[counter &4]); } // End the time tick for 'loopTime console.timeEnd("loopTime"); }